Hisense is making a deliberate play for South Africa’s growing gaming and hybrid-work audience with the launch of its latest monitor lineup, led by…
Facebook’s Rosetta can understand the text in your advice animal memes

Facebook has this week announced its machine-learning program that can read and understand text in images.
This AI system, which Facebook calls Rosetta, will allow the company to read text from images on its social network, be it your advice animal memes, or road signs in photographs.
“Understanding the text that appears on images is important for improving experiences, such as a more relevant photo search or the incorporation of text into screen readers that make Facebook more accessible for the visually impaired,” the company explained in the announcement.
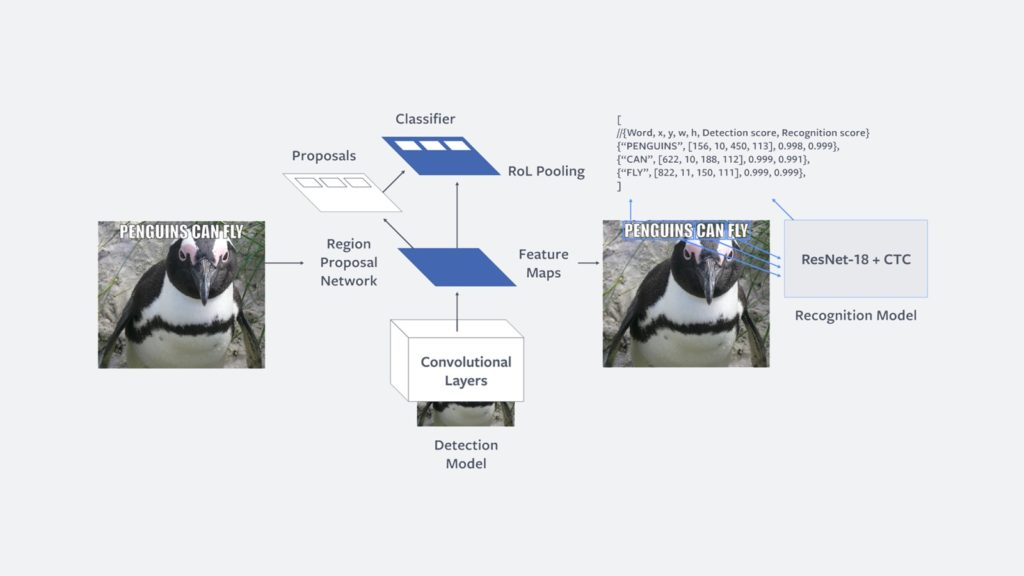
According to Facebook, Rosetta uses a two-step text extraction process.
“In the first step, we detect rectangular regions that potentially contain text. In the second step, we perform text recognition”, Facebook explained.
When a possible region is detected, a convolutional neural network (CNN) read the words. It calls this the Faster R-CNN, which allows the detection and recognition of words to happen almost simultaneously. Once text regions are found, they are highlighted, cropped and sent as a batch for processing.
The system doesn’t read every image online though, only those that pass a certain threshold make it through to detection and recognition.
Facebook claims that it can process more than a billion images per day using Rosetta.
Text extraction isn’t limited to English or the Roman alphabet either.
“We currently support different languages and encodings such as, among others, Arabic and Hindi, in a unified model,” the company added.
The system could be widely useful for online safety too, as it could be employed by Facebook and its other social media products detect harmful or hateful images.
At present, Rosetta “has been widely adopted by various products and teams within Facebook and Instagram” but its future development points to additional languages and text recognition in video content.
Feature image: Facebook

